
How AWS builds things: Amazon Builder's Library. TLDR.
AWS publishes PDFs containing tips and tricks for building scalable systems. We tried to trim the fat and present valuable points from each article in around two paragraphs. The PDFs are from March 5th 2022, so articles posted after that date aren’t included. Star review ratings are given.
Contents
- Using load shedding to avoid overload (
 )
) - Workload isolation using shuffle-sharding ()
- Timeouts, retries, and back off with jitter ()
- Static stability using Availability Zones ()
- Reliability, constant work, and a good cup of coffee ()
- Minimizing correlated failures in distributed systems ()
- Making retries safe with idempotent APIs ()
- Leader election in distributed systems ()
- Instrumenting distributed systems for operational visibility ()
- Implementing health checks ()
- Going faster with continuous delivery ()
- Fairness in multi-tenant systems ()
- Ensuring rollback safety during deployments ()
- Challenges with distributed systems ()
- Caching challenges and strategies ()
- Building dashboards for operational visibility ()
- Avoiding insurmountable queue backlogs ()
- Avoiding fallback in distributed systems ()
- Avoiding overload in distributed systems by putting the smaller service in control ()
- Automating safe, hands-off deployments ()
Using load shedding to avoid overload
Tips for not killing your services by overloading them:
Shed requests which would cause load to get too high and lead to performance degradation. Don’t forget to filter out latency measurements for rejected requests from measurements for client RPC calls. Also, make sure that the shedding threshold is not set lower than the reactive scaling threshold. If you forget, reactive scaling will not trigger.
Drop doomed requests by making clients include a timeout hint. When the timeout is reached server-side, kill the request. Keep the timeout hint relevant by subtracting the time taken by a service before passing the request downstream. Be aware of clock sync issues there. Similarly, check a request to see if it has been sitting in a queue for a long time, before starting to work on it. Throw it out if it’s too old, to get to the fresher requests sooner.
Pagination helps to avoid wasted work and makes it easier to estimate the time to respond to a request. Return an iterator or similar instead of a large result. When API’s are multi-step and include, for example, start and end calls, prioritize end calls so that clients who began their request can finish them.
Workload isolation using shuffle-sharding
Shuffle sharding is a technique to improve reliability of a client fleet who share common resources or dependencies. For example, if you have clients who need work done, and workers, you want to match clients to workers in a many-to-many fashion so that the failure of an individual worker effects as few clients as possible. If you have n clients and m workers and each client requires k workers with k < m then you should try to make sure that the size of the overlap between the sets of k workers assigned to any two clients is minimized.
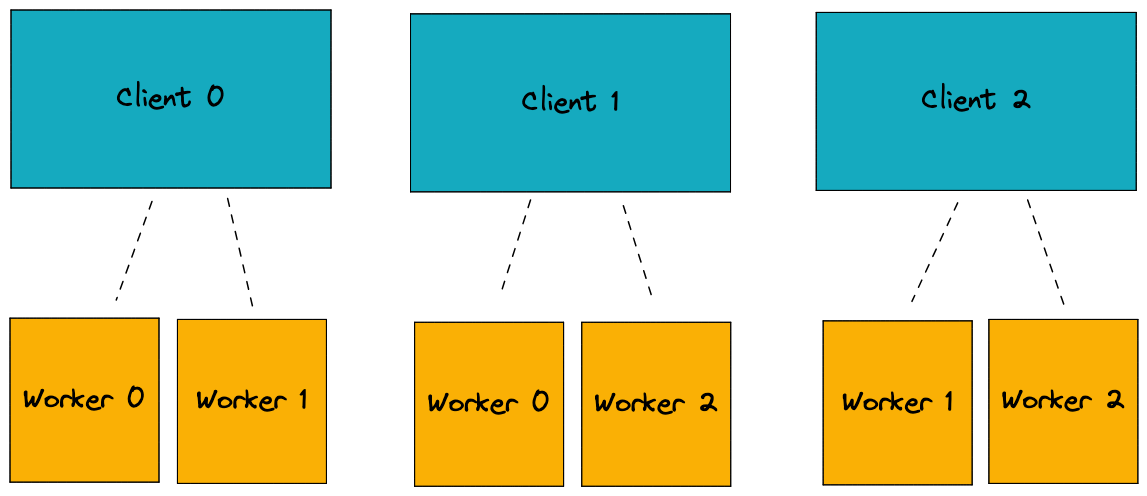
The image shows a configuration where two workers are assigned to each client. Even if both workers of a single client fail, the other clients will still have a functioning worker.
The technique is more useful if resource failure is correlated to a client. For instance, if a client comes under DDOS attack then their workers may fail quickly.
Timeouts, retries, and back off with jitter
Use capped exponential back off to avoid overloading a system with retries. Combine this with a token bucket algorithm. Add jitter to any timers in the system, but make it deterministic and not random, to make debugging easier.
Static stability using Availability Zones
Aim for static stability, meaning being stable in the face of failure without needing to add resources after the fact. In practice it means having resources on standby. When a failure occurs the service can use the backup resources until the failed resources are replaced.
Reliability, constant work, and a good cup of coffee
Improve stability by always doing the same amount of work instead of varying and scaling up the amount of work. If there isn’t work then create dummy work. The reduced variance is more predictable and there will be fewer ways for your system to fail. A good example is having a downstream service read configuration from an upstream service in a loop, instead of pushing from the upstream service on changes. It requires less logic and savings in dev and maintenance cost might make up for added computation.
Minimizing correlated failures in distributed systems
Use random jitter in time based operations to reduce the chance of correlated failures. It’s a good idea to use a value like the server IP address as a seed to help with debugging.
Making retries safe with idempotent APIs
For particular services it is worth publishing an idempotency contract. The API contains a clientToken parameter, which identifies client requests. The service caches requests and results and returns cached results when a duplicate clientToken is received. The parameters of requests are also stored, and if the clientToken matches but the parameters are different, then the service returns an error. In this way you assume that the client made an error if sending two differently parameterized requests with the same token. Amazon found it reasonable to expire cached results after a certain time.
Leader election in distributed systems
Use a distributed lock service to elect a leader. The devil is in the details of course…
Instrumenting distributed systems for operational visibility
Use logs to help you and your clients debug and anticipate problems. In particular
- Pass around trace id’s to help connect log statements between services.
- Pass around metric aggregation objects to log a comprehensible set of metrics at the end of a processing pipeline.
- Test logging at max throughput and consider logging to different disk partitions, a ramdisk or temporary file system, or writing compressed logs. Be sure to use a compression algorithm that can handle truncation.
- Rotate logs frequently to spread out the work done to transfer or compress the data, and avoid spikes in resource utilization. Do this even if it means slightly more work overall.
- Use opt-in for logging sensitive data.
Implementing health checks
Ensure servers provide their software version in health checks, so that zombie servers (disconnected servers that reconnect after a long time) are noticed. Also, beware the black hole phenomenon; failed servers respond to requests faster and take a greater portion of work from the load balancer.
Going faster with continuous delivery
This must be an old article: it contains standard CI/CD ideas.
Fairness in multi-tenant systems
Use token-bucket like algorithms to rate limit clients. It’s a good idea to give services greater quotas when they start up, as the workload may be higher due to downloading updates.
Using quotas raises the question of how to scale quota tracking services. For example, consider a packet stream with a large number of different users sending packets. It should be possible to rate limit each user using a constant memory algorithm, even if the users all have different quotas.
We diverge from the article here as it mentions algorithms ‘Heavy Hitter, Top Talkers and Counting Bloom Filters’ and we could only find a canonical description of a Counting Bloom Filter. The algorithms are for a problem class known as Top-k. An online algorithm for the Top-k problem finds the k most frequent elements from an online stream. A solution does not also solve the rate limiting problem if each user has a different quota. We assume the strategy (omitted in the article) is to only periodically compare element counts provided by e.g. a Counting Bloom Filter, with the quota.
Ensuring rollback safety during deployments
Deploy changes to fleets of services using Two Phase Deployment: make two waves of changes. The first wave ensures both backwards compatibility with the initial state and forwards compatibility with the changes made in the second wave. The second wave of changes can be rolled back, and because the first wave ensured forward compatibility, there will be no lasting damage.
For example, if upgrading communication to use Json instead of XML then first upgrade servers to read Json (and XML), and only then upgrade them to also write Json.
Do test the ability to roll changes forward and backwards, in a production-like test environment.
Challenges with distributed systems
Skipped it.
Caching challenges and strategies
You can differentiate caching strategies by cache placement. You could place a standalone (on-box) cache in front of each server of a service, or you could have a separate caching service (external) in front of the service. With the on-box approach, you deal with cache coherence problems. Consistency is easier using the external cache, but that implies maintaining another service.
For all caching solutions, consider using soft and hard time-to-live (TTL) values. Clients will try to refresh cached values when the soft TTL expires, but can rely on reading cached values until the hard TTL expires. Stressed services can apply back pressure by telling clients to ignore the soft TTL until the hard TTL expires.
Don’t forget to cache negative values: error messages or other values for failed requests. Otherwise, the cache will not relieve a failed service. Also ensure at most one instance of a request to the target service may be outstanding at a time.
Test your cached systems to see what happens if the cache fails or requires repopulating. Test the impact of adding and removing cache nodes, as consistent hashing implementations and their properties may differ between cache products. Be aware of security issues; caches are targets for attackers trying to fill them with foreign values, and the difference between response time for cached and non-cached requests can give information (side channel attack).
Building dashboards for operational visibility
The article contains wisdom on making good dashboards. We forgo a summary and suggest reading a dedicated UX design book instead.
Avoiding insurmountable queue backlogs
Processing failures can lead to queue backlogs. If adding extra processing capacity is not enough to clear the backlog then try switching queues to LIFO mode, if it is possible for the application.
Avoiding fallback in distributed systems
A fallback is an alternative strategy used to do something when the regular way of doing that thing fails. In this definition, retrying against the same endpoint or a different but equivalent endpoint is not a fallback. An example of a fallback is using a different memory allocator when the call to the default allocator fails.
Avoid fallbacks. They are hard to test and they are only triggered in chaotic situations which can make things more chaotic. Put more effort into making the default behavior more reliable.
Avoiding overload in distributed systems by putting the smaller service in control
Running services are often split into data and control planes. The data plane runs the application and the control plane takes care of configuration. There are three broad syncing strategies:
- The data plane pulls from the control plane.
- The control plane pushes to the data plane.
- Both planes communicate via shared scalable object store.
Each strategy has pros and cons. In (1) the data plane can overload the control plane. (2) avoids the problem but takes more work to implement; control plane servers need to know of active data plane servers via some kind of heartbeat service, and they also need to agree on subsets of data plane servers to serve (via consistent hashing). (3) may be reliable but might it might be hard to deal with staleness and keep latencies down.
There is a (4)th, in between, solution, where data plane servers reach out to control plane servers via a lightweight message (UDP) and control servers respond to these messages in their own time by opening direct channels to the respective data plane server.
Automating safe, hands-off deployments
At Amazon, source code is not the only data that goes through CI/CD pipelines. Source code, tests, tools, assets, configuration, infrastructure and operating systems or patches all have pipelines. A pipeline is made of a number of stages and includes building, testing and deployment. The deployment stage is made of waves. Each wave has a successively shorter duration and includes deploying to a successively larger number of deployment machines or regions. Attention is paid to automatically monitor alarms to either block progressing to a next stage, or to rollback completely.